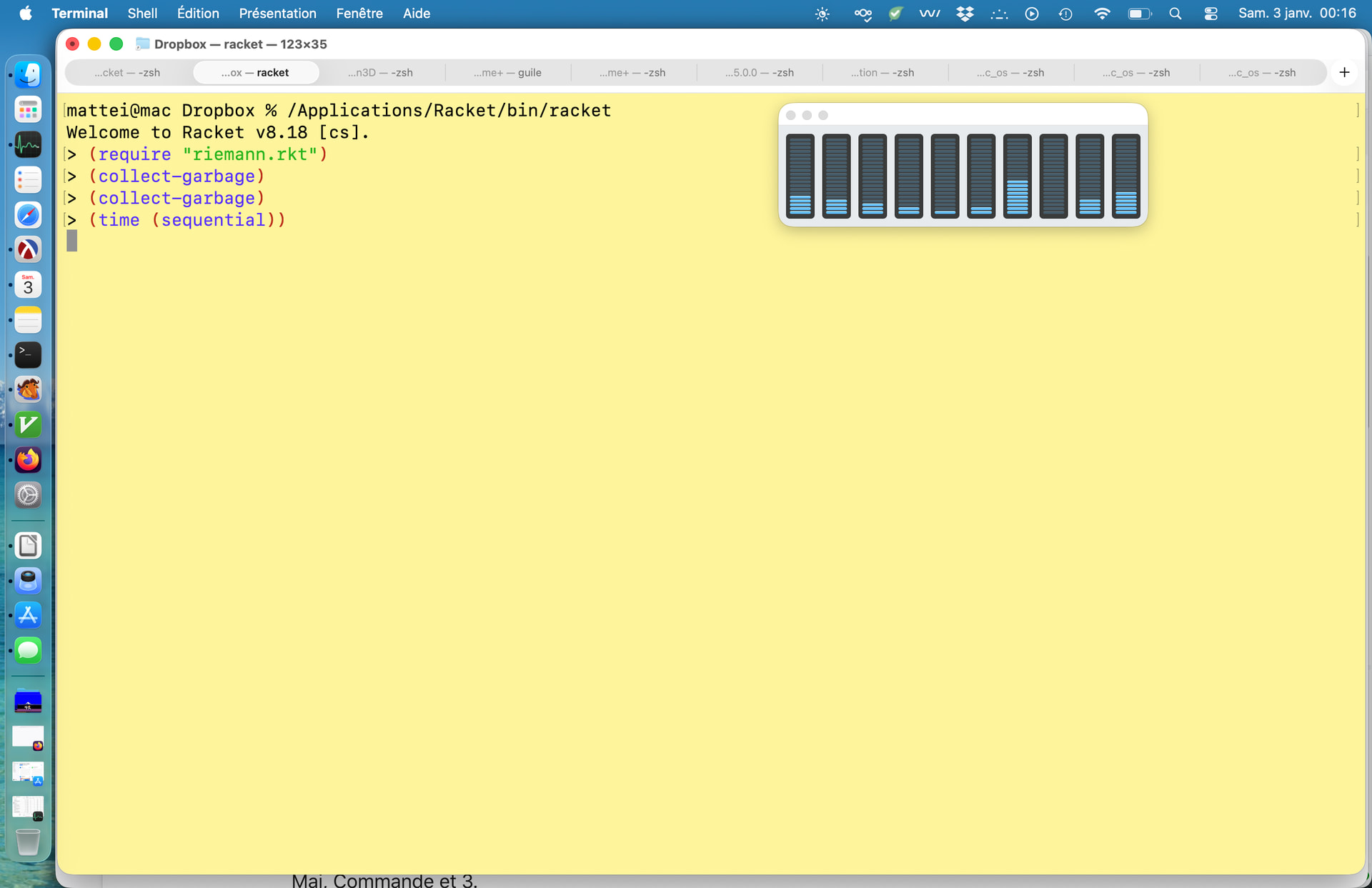
Not so bad with Racket/future in command line interface, compared to C++/Kokkos (OpenMP):
one can see in sequential that 10 cores are lightly used.
in // the 10 cores are heavily loaded.
and the result is faster:
factor >2 but with 10 cores.
Comparing with C++/Kokkos on 1 core:
And with 10 cores,again coresare loaded:
and the speed:
factor of 4 but still with 10 cores.
and approx 3.5times faster than Racket
The code used:
#lang racket
(module+ main
(printf ";; Sequential:\n")
(collect-garbage)
(collect-garbage)
(collect-garbage)
(time (sequential))
(printf ";; Parallel (~v cores):\n" (processor-count))
(collect-garbage)
(collect-garbage)
(collect-garbage)
(time (parallel)))
(provide sequential
parallel)
(require racket/flonum
math/flonum)
(define Function flsin)
#;
(define numSubdivisions 1000000000) ; -> 2.000000000001576
(define numSubdivisions 100000000) ; -> 1.9999999999999005
;;^ with (sequential), parallel result is 1.9999999999999791
(define A 0.0)
(define B pi)
#;(define dx
(fl/ (fl- B A)
(->fl (sub1 numSubdivisions))))
(define dx
(fl/ (fl- B A)
(->fl numSubdivisions)))
#;(define init-sum
(fl/ (fl+ (Function A) (Function B))
2.0))
(define iter 500)
(define (sequential)
(define result 0)
(for ((t (in-range iter)))
(set! result (fl* (for/fold ([sum 0.0 #;init-sum])
([i (in-range 1 (add1 #;sub1 numSubdivisions))])
(define x
(fl+ A (fl* dx (->fl i))))
(define f
(Function x))
(fl+ sum f))
dx))
)
result
)
(define (parallel)
(define result 0)
(for ((t (in-range iter)))
(define cpus
(processor-count))
(define jobs
(for/list ([job (in-inclusive-range 1 cpus)])
(future
(λ ()
(for/fold ([sum 0.0])
([i (in-range job (add1 #;sub1 numSubdivisions) cpus)])
(define x
(fl+ A (fl* dx (->fl i)))) ; A + dx * i
(define f
(Function x))
(fl+ sum f))))))
(set! result (fl* (flsum ;(cons init-sum
(map touch jobs));)
dx))
)
result
)
C++/Kokkos :
#include <limits>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <Kokkos_Core.hpp>
int main( int argc, char* argv[] )
{
const int N = 100000000; // nombre de sous-intervalles
const double a = 0.0;
const double b = M_PI;
const double dx = (b - a) / N;
int nrepeat = 30; // number of repeats of the test
// Read command line arguments.
for ( int i = 0; i < argc; i++ ) {
if ( strcmp( argv[ i ], "-nrepeat" ) == 0 ) {
nrepeat = atoi( argv[ ++i ] );
}
else if ( ( strcmp( argv[ i ], "-h" ) == 0 ) || ( strcmp( argv[ i ], "-help" ) == 0 ) ) {
printf( " riemann Options:\n" );
printf( " -nrepeat <int>: number of repetitions (default: 100)\n" );
printf( " -help (-h): print this message\n\n" );
exit( 1 );
}
}
Kokkos::initialize( argc, argv );
{
// Timer products.
Kokkos::Timer timer;
for ( int repeat = 0; repeat < nrepeat; repeat++ ) {
// Application: riemann integral
double integral = 0.0;
Kokkos::parallel_reduce( "RiemannIntegral",
N,
KOKKOS_LAMBDA ( int i, double &local_sum ) {
double x = a + i * dx;
local_sum += Kokkos::sin(x); //std::sin(x);
},
integral );
integral *= dx;
// Output result.
if ( repeat == ( nrepeat - 1 ) ) {
printf( " Computed result for Integral is %lf\n", integral );
}
}
double time = timer.seconds();
// Print results (problem size, time and bandwidth in GB/s).
printf( " N( %d ) nrepeat ( %d ) time( %g s ) \n",
N, nrepeat, time );
}
Kokkos::finalize();
return 0;
}
If i test it on may Linux box:
My Linux Intel7 box seems really slower than Apple M4 even with the 16 cores,and only in // it can save the game a little:
with a factor speedup of 6 with the 16 cores , this is not really what i expected from //.
Let see with C++/Kokkos if it performs better? :
can see it runs well on 16 cores
More than half the time of Racket ,i expected better from C++/Kokkos
The serial run on only one cpu give this time:
About all the articles about computer architecture we can find on the net, i admit it is a bit confusing.I think there is a gap between the guys that do the CPU architecture, and the ones who wrote compilers, and at last the programmers. A lot of times I can personnally hardly find what concretely i can do of all those informations.
"But building programmable hardware that only 5 people in the world can program ain’t a winning strategy, I’d humbly suggest." (from linked article)